11 Analiza kodu
Programując naszym celem jest tworzenie funkcji, które są zarówno poprawne oraz wydajne (zwracają wynik szybko). W tym rozdziale przedstawione będą testy jednostkowe, które sprawdzają czy funkcje zwracają oczekiwany wynik oraz metody sprawdzające wydajność funkcji, takie jak, profiling i benchmarking.
11.1 Testy jednostkowe
Testy jednostkowe (ang. unit tests) to sposób sprawdzania czy stworzona przez nas funkcja działa w sposób jaki oczekujemy. Tworzenie takich testów wymusza także myślenie na temat odpowiedniego działania funkcji i jej API. Testy jednostkowe są najczęściej stosowane w przypadku budowania pakietów (sekcja 15.10), gdzie możliwe jest automatyczne sprawdzenie wielu testów na raz. Przykładowo, napisaliśmy nową funkcję, która wykonuje złożone operacje i, po wielu sprawdzeniach, wiemy, że daje poprawne wyniki. Po kilku miesiącach wpadliśmy na pomysł jak zwiększyć wydajność naszej funkcji. W tym momencie wystarczy już tylko stworzyć nową implementację i użyć wcześniej zbudowanych testów. Dadzą one informację, czy efekt działania jest taki jaki oczekujemy, a w przeciwnym razie wskażą gdzie pojawił się błąd. Istnieje też dodatkowa reguła - jeżeli znajdziesz błąd w kodzie od razu napisz test jednostkowy.
Zobaczmy jak działają testy jednostkowe na przykładzie funkcji nowy_prostokat() oraz powierzchnia() stworzonych w sekcji 10.3.
nowy_prostokat = function(xmin, ymin, xmax, ymax){
if (!all(c(length(xmin), length(ymin), length(xmax), length(ymax)) == 1)){
stop("Każdy z argumentów może przyjmować tylko jedną wartość")
}
vals = c(xmin, ymin, xmax, ymax)
if (!(is.numeric(vals))){
stop("Wszystkie argumenty muszą być typu numerycznego")
}
x = matrix(vals, ncol = 2)
structure(x, class = "prostokat")
}
powierzchnia = function(x) {
UseMethod("powierzchnia")
}
powierzchnia.prostokat = function(x){
a = x[1, 2] - x[1, 1]
b = x[2, 2] - x[2, 1]
a * b
}Jednym z możliwych narzędzi do testów jednostkowych w R jest pakiet testthat (Wickham 2020).
library(testthat)Zawiera on szereg funkcji sprawdzających czy działanie naszych funkcji jest zgodne z oczekiwaniem.
Funkcje w tym pakiecie rozpoczynają się od prefiksu expect_ (oczekuj).
W przypadku funkcji powierzchnia() oczekujemy, że wynik będzie zawierał tylko jeden element.
Możemy to sprawdzić za pomocą funkcji expect_length().
nowy_p = nowy_prostokat(0, 0, 6, 5)
expect_length(powierzchnia(nowy_p), 1)Jeżeli wynik ma długość jeden to wówczas nic się nie stane. W przeciwnym razie pojawi się komunikat błędu.
Wiemy, że powierzchnia naszego przykładowego obiektu nowy_p to 30.
Do sprawdzenia, czy nasza funkcja daje na tym obiekcie dokładnie taki wynik możemy użyć expect_equal().
expect_equal(powierzchnia(nowy_p), 30)W momencie, gdy wynik jest zgodny to nie nastąpi żadna reakcja, a w przeciwnym razie wystąpi błąd.
W pakiecie testthat istnieją inne funkcje podobne do expect_equal().
Przykładowo, funkcja expect_identical() sprawdza nie tylko podobieństwo wartości, ale też to czy klasa wyników jest taka sama.
Aby sprawdzić czy nasza funkcja na pewno zwróci błąd w przypadku podania niepoprawnych danych wejściowych możemy użyć funkcji expect_error().
Jej działanie jest przedstawione poniżej.
expect_error(nowy_prostokat(3, 5, 2, "a"))
expect_error(nowy_prostokat(1, 2, 3, 6))
#> Error: `nowy_prostokat(1, 2, 3, 6)` did not throw an error.W przypadku, gdy wywołanie funkcji zwróci błąd, expect_error() nic nie zwróci.
Natomiast, jeżeli wywołania funkcji nie zwróci błędu, expect_error() zatrzyma swoje działanie i zwróci komunikat.
Odpowiednikami expect_error() dla ostrzeżeń jest expect_warning(), a dla wiadomości expect_message().
Pozostałe funkcje z tego pakietu są wymienione i opisane na stronie https://testthat.r-lib.org/reference/index.html.
11.2 Profiling
Istnieją trzy podstawowe reguły optymalizacji kodu45:
- Nie.
- Jeszcze nie.
- Profiluj przed optymalizowaniem.
Czym jest profilowanie i dlaczego powinno być wykonywane przed optymalizowaniem kodu? Profilowanie mierzy wydajność działania każdej linii kodu w celu sprawdzenia, która linia zabiera najwięcej czasu lub zasobów. Dzięki profilowaniu można określić fragmenty kodu, które można poprawić w celu zwiększenia czasu wykonywania skryptu czy funkcji.
Poniżej znajduje się zawartość pliku R/moja_funkcja.R.
Jego działanie polega na stworzeniu wektora od 1 do 9999999 (obiekt x), wektora od 1 do 19999998 co 2 (obiekt y), połączenie tych wektorów do ramki danych (obiekt df), wyliczenie sumy wartości dla każdego wiersza (obiekt z), a na końcu wyliczenie średniej z obiektu z.
Która z tych linii zabiera najwięcej czasu a która najmniej?
# plik R/moja_funkcja.R
x = 1:9999999
y = seq(1, 19999998, by = 2)
df = data.frame(x = x, y = y)
z = rowSums(df)
mean(z)Profilowanie kodu R można wykonać używając funkcji profvis() z pakietu profvis (Chang, Luraschi, and Mastny 2019).
Przyjmuje ona kod lub funkcję, która ma zostać profilowana.
library(profvis)
profvis(source("R/moja_funkcja.R"))W powyższym przypadku nastąpiło profilowanie kodu zawartego w skrypcie R/moja_funkcja.R.
Efektem działania jest interaktywne podsumowanie pokazujące zużycie pamięci oraz czas poświęcony dla kolejnych linii kodu (rycina 11.1).
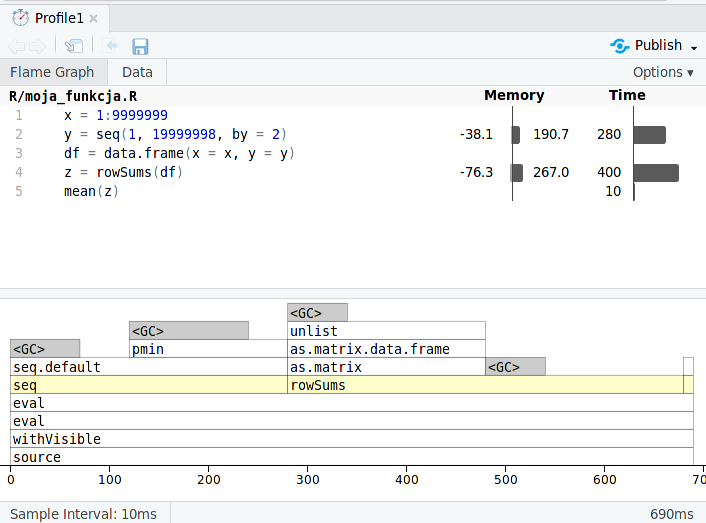
Rycina 11.1: Zrzut ekranu przedstawiający wynik działania funkcji profvis().
Czas wykonania tego przykładu wyniósł sumarycznie 690ms.
Pierwsza linia tworząca obiekt x została wykonana bardzo szybko - poniżej mierzalnego progu.
Stworzenie obiektu y w drugiej linii zajęło ok. 280ms.
Trzecia linia została wykonana również w czasie poniżej mierzalnego progu.
Wynika to z kwestii, że tworzenie tam ramki danych nie powoduje wykonania nowych, złożonych obliczeń.
Powstała ona jedynie poprzez przekazanie odpowiednich adresów w pamięci do obiektów x i y.
Najbardziej czasochłonną okazała się linia czwarta.
Wyliczenie sum wierszy i stworzenie obiektu z zabrało ok. 400ms.
Ostatnia linia, wyliczająca średnią, zabrała ok. 10ms.
11.3 Benchmarking
Benchmarking oznacza określanie wydajności danej operacji czy funkcji.
Wydajność może być określona na wiele różnych sposobów, w tym najprostszym jest czas wykonania pewnego kodu.
Do określenia ile czasu zajmuje działanie operacji można użyć wbudowanej funkcji system.time().
system.time(kod_do_wykonania)Przykładowo, poniżej nastąpi sprawdzenie czasu jaki zajmie wyliczenie średniej wartości z sekwencji od 1 do 100000000.
system.time(mean(1:100000000))
#> user system elapsed
#> 0.571 0.001 0.570W efekcie dostajemy trzy wartości - user, system i elapsed. Pierwsza z nich określa czas obliczenia po stronie użytkownika (sesji R), druga opisuje czas obliczenia po stronie systemu operacyjnego (np. otwieranie plików), a trzecia to sumaryczny czas wykonywania operacji.
Benchmarking jest często używany w sytuacji, gdy istnieje kilka funkcji służących do tego samego celu (np. w różnych pakietach) i chcemy znaleźć tę, która ma najwyższą wydajność. Jest on też stosowany, gdy sami napisaliśmy kilka implementacji rozwiązania tego samego problemu i chcemy sprawdzić, które z nich jest najszybsze.
W sekcji 8.1.2 stworzyliśmy kilka wersji pętli for pozwalającej na przeliczanie wartości z mil lądowych na kilometry.
Pierwsza z nich, tutaj zdefiniowana jako funkcja mi_do_km1, tworzy pusty wektor o długości 0, do którego następie doklejane są kolejne przeliczone wartości.
mi_do_km1 = function(odl_mile){
odl_km = vector("list", length = 0)
for (i in seq_along(odl_mile)) {
odl_km = c(odl_km, odl_mile[[i]] * 1.609)
}
odl_km
}Druga, tutaj zdefiniowana jako funkcja mi_do_km2, tworzy pusty wektor o oczekiwanej długości wyniku.
Następnie kolejne przeliczone wartości są wstawiane w odpowiednie miejsca wektora wynikowego.
mi_do_km2 = function(odl_mile){
odl_km = vector("list", length = length(odl_mile))
for (i in seq_along(odl_mile)) {
odl_km[[i]] = odl_mile[[i]] * 1.609
}
odl_km
}Dwie powyższe funkcje można porównać używając system.time().
Nie zawsze jednak to wystarczy - ta sama funkcja wykonana dwa razy może mieć różny czas obliczeń.
Dodatkowo, oprócz czasu wykonywania funkcji może nas interesować zużycie zasobów, takich jak pamięć operacyjna.
Do takiego celu powstała funkcja mark() z pakietu bench (Hester 2020), która wykonuje funkcje wiele razy przed zwróceniem wyniku.
Przyjmuje ona wywołania funkcji, które chcemy porównać.
Poniżej nastąpi porównanie funkcji mi_do_km1 i mi_do_km2, w przypadku gdy jako dane wejściowe zostanie podana lista z wartościami 142, 63, 121.
library(bench)
odl_mile = list(142, 63, 121)
wynik_1 = mark(
mi_do_km1(odl_mile),
mi_do_km2(odl_mile)
)
wynik_1
#> # A tibble: 2 × 6
#> expression min median itr/se…¹ mem_a…²
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:b>
#> 1 mi_do_km1(odl_mile) 1.7µs 1.9µs 491429. 27.5KB
#> 2 mi_do_km2(odl_mile) 1.3µs 1.4µs 668219. 27.8KB
#> # … with 1 more variable: `gc/sec` <dbl>, and
#> # abbreviated variable names ¹`itr/sec`, ²mem_allocEfektem porównania jest ramka danych, w której każdy wiersz oznacza inną porównywaną funkcję. Zawiera ona szereg charakterystyk, w tym:
min- minimalny czas wykonania funkcjimean- średni czas wykonania funkcjimedian- mediana czasu wykonania funkcjimax- maksymalny czas wykonania funkcjiitr/sec- liczba wykonań funkcji na sekundęmem_alloc- pamięć użyta przez wywołanie funkcjin_itr- liczba powtórzeń wywołania funkcji
Wynik działania funkcji mark() pozwala na zauważenie, że na tym przykładzie funkcja mi_do_km2 jest ok. 30% szybsza od mi_do_km1.
Czasami możliwe jest, że jakaś funkcja działa relatywnie szybko na małych danych, ale dużo wolniej na większych danych wejściowych.
Warto jest więc sprawdzić, jak będzie wyglądało nasze porównanie na większej liście, np. z wartościami od 0 do 10000 co 1.
odl_mile2 = as.list(0:10000)
wynik_2 = mark(
mi_do_km1(odl_mile2),
mi_do_km2(odl_mile2)
)
#> Warning: Some expressions had a GC in every iteration;
#> so filtering is disabled.
wynik_2
#> # A tibble: 2 × 6
#> expression min median itr/s…¹ mem_a…²
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:b>
#> 1 mi_do_km1(odl_mile2) 436ms 458ms 2.18 382MB
#> 2 mi_do_km2(odl_mile2) 864µs 889µs 1020. 78.2KB
#> # … with 1 more variable: `gc/sec` <dbl>, and
#> # abbreviated variable names ¹`itr/sec`, ²mem_allocW tym przypadku różnica pomiędzy mi_do_km1 a mi_do_km2 staje się dużo większa.
Funkcja mi_do_km1 jest w stanie wykonać tylko 2.18 operacji na sekundę, przy aż 1020.42 operacji na sekundę funkcji mi_do_km2.
Dodatkowo, funkcja mi_do_km1 potrzebowała aż kilka tysięcy (!) razy więcej pamięci operacyjnej niż mi_do_km2.
11.4 Zadania
set.seed(2019-05-08)
mat = matrix(c(sample(1:10, size = 25, replace = TRUE)),
ncol = 5, nrow = 5)
mat
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 6 1 2 4 6
#> [2,] 9 9 9 5 5
#> [3,] 2 6 4 8 10
#> [4,] 4 6 1 2 5
#> [5,] 2 10 6 4 9Korzystając z wiedzy z rozdziału 8 dotyczącej pętli
for, napisz funkcjęgdzie_naj(), która przyjmuje na wejściu macierz z wartościami numerycznymi, wylicza sumę wartości dla każdego wiersza, a następnie zwraca numer wiersza z najwyższą sumą wartości. Przykładowe dane wejściowe do tej funkcji znajdują się nad tym zadaniem.Dodaj do powyższej funkcji odpowiednie komunikaty błędów czy ostrzeżeń (sekcja 10.2), pojawiające się w zależności od rodzaju wprowadzonych danych wejściowych.
Napisz testy jednostkowe sprawdzające (1) czy błędy pojawiają się w odpowiednich sytuacjach oraz (2) czy funkcja zwraca prawidłową wartość.
Użyj metod profilowania kodu w celu sprawdzenia czasów wykonywania kolejnych linii kodu. Działanie której linii kodu zabiera najwięcej czasu?
Stwórz funkcję
gdzie_naj2(), której cel jest taki sam jak funkcjigdzie_naj(), ale zamiast pętliforjej działanie oparte jest o funkcjęrowSums().Używając pakietu bench porównaj czas działania funkcji
gdzie_naj()igdzie_naj2(). Która z nich jest szybsza? Która z nich zużywa mniej zasobów?
Bibliografia
Chang, Winston, Javier Luraschi, and Timothy Mastny. 2019. Profvis: Interactive Visualizations for Profiling R Code. https://CRAN.R-project.org/package=profvis.
Hester, Jim. 2020. Bench: High Precision Timing of R Expressions. https://CRAN.R-project.org/package=bench.
Wickham, Hadley. 2020. Testthat: Unit Testing for R. https://CRAN.R-project.org/package=testthat.