16 Podsumowanie
Nie jest możliwe, aby jedna książka wyczerpująco pokazywała wszystkie elementy języka programowania i podawała wszelkie jego możliwości i zastosowania. Jest to szczególnie nieosiągalne w przypadku takiego języka jak R, który posiada ogromny zbiór pakietów, oraz społeczność, która używa ten język na wiele sposobów. Celem tego rozdziału jest wskazanie co można zrobić dalej na podstawie uzyskanej wiedzy i umiejętność z tej książki.
16.1 Grafika
Jedną z najczęściej wymienianych zalet R są jego rozbudowane narzędzia do tworzenia wykresów. Możemy to zobaczyć na poniższym przykładzie danych meteorologicznych dla Poznania i Zakopanego z roku 2017.
met = read.csv("https://github.com/Nowosad/elp/raw/master/pliki/dane_meteo.csv")
head(met)
#> kod_stacji nazwa_stacji rok miesiac dzien tavg
#> 1 352160330 POZNAŃ 2017 1 1 1.4
#> 2 352160330 POZNAŃ 2017 1 2 0.1
#> 3 352160330 POZNAŃ 2017 1 3 0.5
#> 4 352160330 POZNAŃ 2017 1 4 1.5
#> 5 352160330 POZNAŃ 2017 1 5 -3.5
#> 6 352160330 POZNAŃ 2017 1 6 -8.4
#> precip
#> 1 0.0
#> 2 0.0
#> 3 4.8
#> 4 2.3
#> 5 0.0
#> 6 0.0Wewnątrz obiektu met znajdują się kolumny tavg (określająca średnią dobową temperaturę powietrza w stopniach Celsjusza) oraz nazwa_stacji (“POZNAŃ” lub “ZAKOPANE”).
Do porównania wartości temperatury pomiędzy stacjami może posłużyć wykres pudełkowy, stworzony przy pomocy funkcji boxplot() (rycina 16.1).
Poniżej zdefiniowano, która zmienna ma zostać zwizualizowana (tavg) w podziale na jakie grupy (nazwa_stacji) z jakiego zbioru danych (met)63.
boxplot(tavg ~ nazwa_stacji, data = met)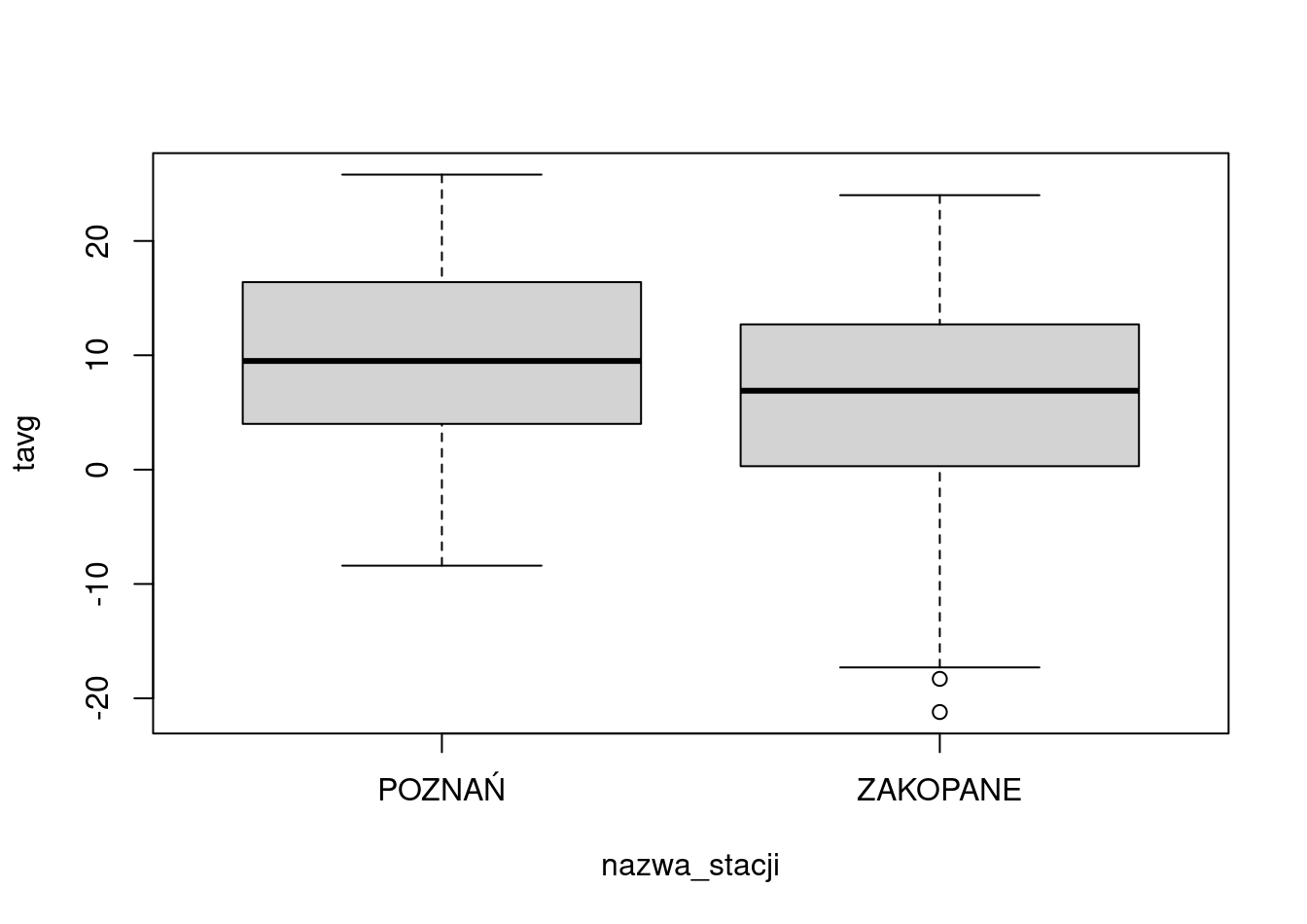
Rycina 16.1: Przykład wykresu utworzonego przy pomocy funkcji boxplot().
Powyższy wykres może być zmodyfikowany używając dodatkowych argumentów (np. main dodający tytuł czy col zmieniający kolor pudełek) czy też dodatkowych funkcji pozwalających na dodanie legendy (funkcja legend) czy też tekstu (funkcja text).
Inne dostępne wbudowane funkcje do tworzenia wykresów to, między innymi, hist() czy barplot() budujące histogramy oraz wykresy słupkowe.
Najbardziej elastyczną funkcją do tworzenia wykresów w R jest plot().
Domyślnie, gdy użytkownik poda wartości numeryczne dla argumentów x i y pozwala ona tworzyć wykresy punktowe.
Jej zachowanie i wynik będzie jednak inne w zależności od tego jakiej klasy będzie obiekt wejściowy, przykładowo inaczej wyświetlony zostanie model liniowy, efekt grupowania hierarchicznego, czy też wynik testu statystycznego.
Oprócz wbudowanych w R funkcji graficznych, istnieje też szereg dodatkowych pakietów służących do wizualizacji danych.
Wśród nich najpopularniejszym jest ggplot2 (Wickham, Chang, et al. 2020).
Ten pakiet jest implementacją założeń zawartych w książce Grammar of Graphics (Wilkinson 2005).
Główną funkcją tego pakietu jest ggplot(), która przyjmuje dane wejściowe w postaci ramki danych.
Wewnątrz tej funkcji następuje wywołanie kolejnej funkcji aes, gdzie definiowane są kolejne kolumny, które mają być wyświetlone na osiach wykresów oraz określają kolor, kształt, wielkość i inne elementy.
Kolejnym krokiem jest określenie typu wykresu poprzez połączenie poprzedniej funkcji (używając operatora +) z jedną z wielu funkcji rozpoczynających się od geom_.
Przykładowo, do stworzenia wykresu pudełkowego służy geom_boxplot() (rycina 16.2).
library(ggplot2)
ggplot(met, aes(nazwa_stacji, tavg)) + geom_boxplot()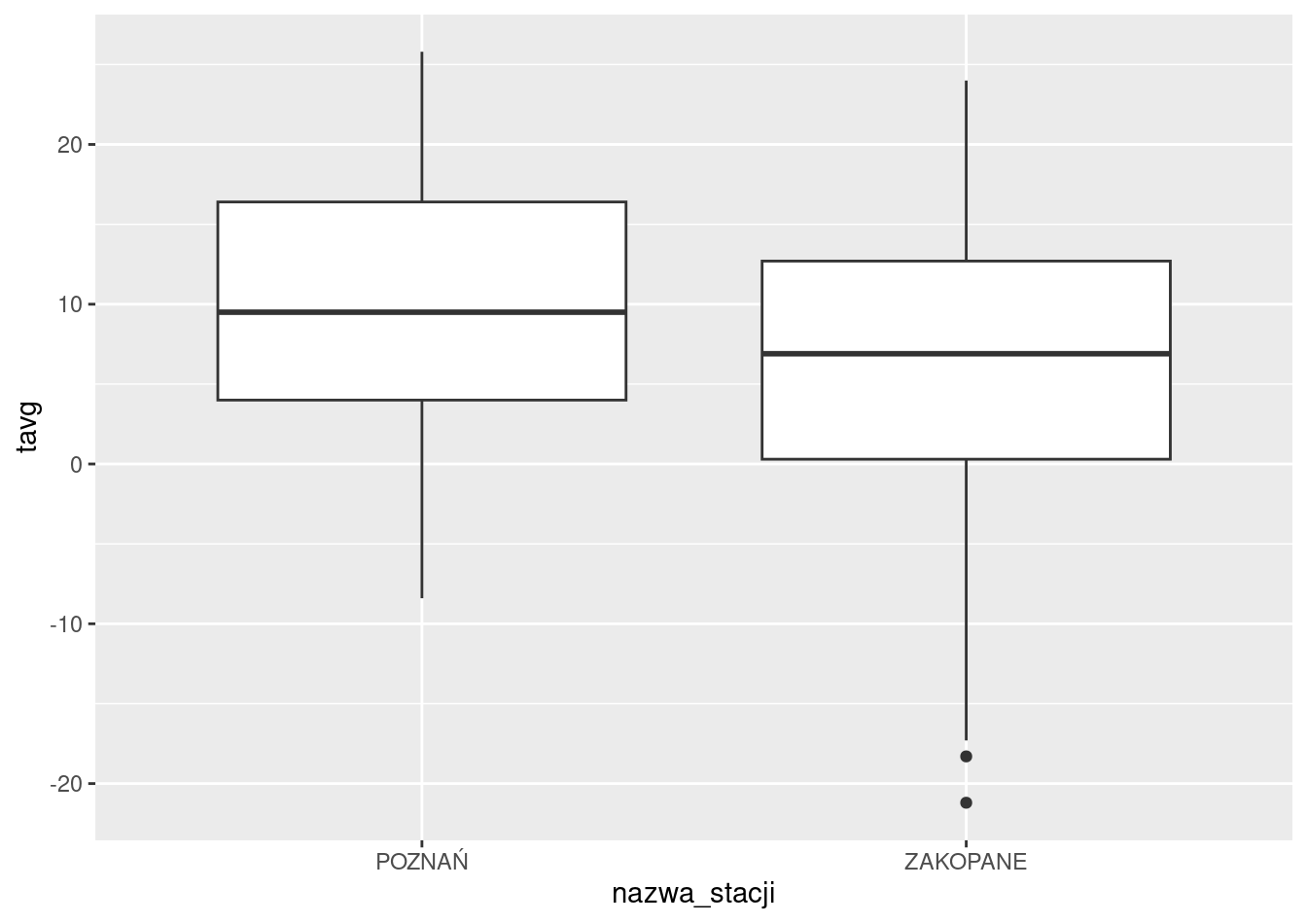
Rycina 16.2: Przykład wykresu utworzonego z użyciem pakietu ggplot2.
Pełna dokumentacja pakietu ggplot2 znajduje się na stronie https://ggplot2.tidyverse.org/.
16.2 Analiza danych
R jest jednym z języków programowania najczęściej używanych w analizie danych64. Jest to wynikiem szeregu przyczyn, w tym dużej liczby wbudowanych w R funkcji statystycznych oraz graficznych. Dodatkowo, ramka danych, jeden z podstawowych obiektów w R, może być utożsamiany z arkuszem kalkulacyjnym czy tabelą z bazy danych - najpopularniejszych form przechowywania różnorakich danych. Ta forma obiektu, złożonego z kolumn (zmienne) i wierszy (obserwacje), jest reprezentacją, która ułatwia czyszczenie, przetwarzanie i analizowanie danych.
Inną przyczyną popularności R do analizy danych jest grupa pakietów zbiorczo określana jako tidyverse. Jest to spójny zbiór pakietów pozwalających na wykonywanie kolejnych czynności analizy danych. Na samym początku obejmuje to pakiety poświęcone wczytywaniu danych w różnych formatach, w tym poznane w rozdziale 9 pakiety readr (Wickham, Hester, and Francois 2018) oraz readxl (Wickham and Bryan 2019). Kolejnym krokiem jest porządkowanie danych, polegające, na przykład, na zmianie struktury ramki danych gdzie wartości jakiejś zmiennej stają się nazwami kolumn. W tym etapie można użyć pakiet tidyr (Wickham and Henry 2020).
Dane w odpowiedniej postaci można następnie przetwarzać, np. tworzyć nowe zmienne na postawie przeliczania już istniejących czy też wyliczać ich podsumowania używając pakietu dplyr (Wickham, François, et al. 2020). Tak przetworzone dane następnie są często wizualizowane używając pakietu ggplot2 (Wickham, Chang, et al. 2020) lub też w ich oparciu budowane są modele. Ma to na celu zrozumienie posiadanych danych oraz zależności czy zjawisk które opisują.
W ramach grupy pakietów tidyverse często stosuje się operator %>% (ang. pipe) z pakietu magrittr (Bache and Wickham 2014).
Pozwala on na łączenie kilku oddzielnych funkcji w jedno zapytanie.
Działanie tego operatora polega na tym, że wynik jednej działania jednej funkcji staje się automatycznie pierwszym argumentem w kolejnej funkcji (rycina 16.3).
library(magrittr)
readxl::read_excel("https://github.com/Nowosad/elp/raw/master/pliki/dane_meteo.xlsx") %>%
tidyr::gather(key = "zmienna", value = "wartosc", tavg:precip) %>%
dplyr::mutate(data = as.Date(paste(rok, miesiac, dzien, sep = "-"))) %>%
ggplot2::ggplot(ggplot2::aes(data, wartosc)) +
ggplot2::geom_line() +
ggplot2::facet_grid(zmienna~nazwa_stacji, scale = "free_y")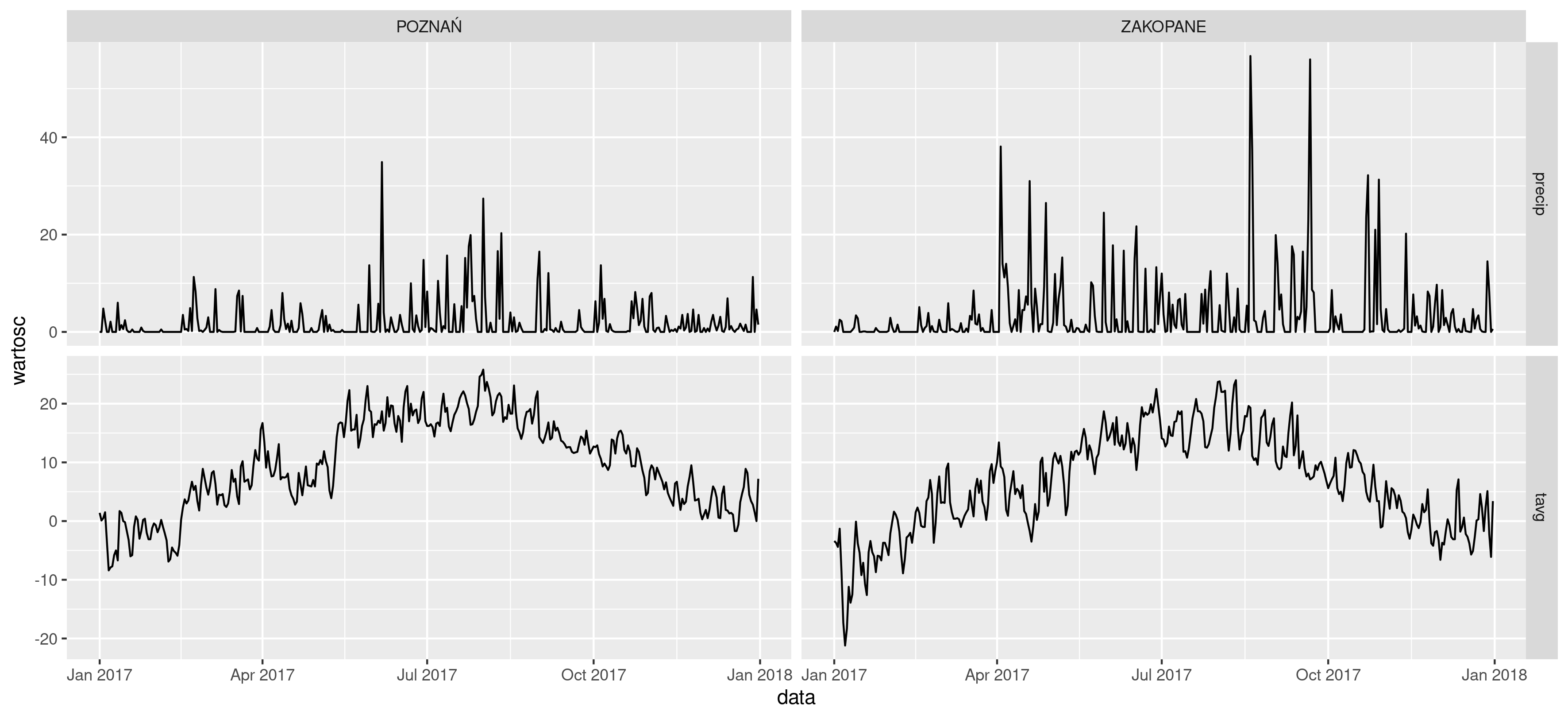
Rycina 16.3: Przykład wyniku użycia pakietów z grupy tidyverse.
Pełne wprowadzenie do koncepcji tidyverse można znaleźć w książce R for Data Science (Wickham and Grolemund 2016).
Zrozumienie zależności czy zjawisk jest bardzo rzadko ostatnim etapem - równie istotne jest przekazanie tych wyników wybranej grupie odbiorców w odpowiedni sposób. Do tego celu może posłużyć R Markdown (jego podstawy zostały opisane w sekcji 15.9) R Markdown pozwala na tworzenie dokumentów w różnych formatach (html, pdf, docx, itd.), prezentacji, stron internetowych, książek65 i wiele innych. Po szczegółowe instrukcje jak używać tego języka warto zajrzeć do książki R Markdown: The Definitive Guide (Xie, Allaire, and Grolemund 2018).
16.3 Inne zastosowania
Wcześniejsze dwie sekcje pokazywały bardzo szerokie zastosowania R - analizować czy wizualizować można zarówno dane o temperaturze powietrza jak i wyniki wyborów prezydenckich. W związku z czym, w R istnieje także znacząca liczba pakietów stworzonych do bardziej specjalistycznych i szczegółowych celów. Można to zobaczyć przeglądając tzw. task views - listy pakietów zagregowane według podobnej tematyki znajdujące się pod adresem https://cran.r-project.org/web/views/. Obejmuje to bardzo szeroki przekrój tematów - od list poświęconych projektowaniu prób klinicznych, poprzez przetwarzanie języka naturalnego, skończywszy na ekonometrii i analizach finansowych66.
Wśród tych list znajduje się także jedna poświęcona analizie danych przestrzennych.
Opisuje ona, między innymi, takie pakiety jak sf, pozwalający na wczytywanie, przetwarzanie i zapisywanie danych wektorowych czy tmap ułatwiający tworzenie map.
Na poniższym przykładzie następuje dołączenie tych pakietów oraz wczytanie zbioru danych World zawierającego poligony krajów na świecie i podstawowe informacje o nich.
Dalej następuje dodanie tych danych do wyświetlenia i wybór odwzorowania przestrzennego używając funkcji tm_shape(), po czym te dane są wyświetlone w postaci poligonów (funkcja tm_polygons()), gdzie kolory poligonów wynikają z ich wartości w kolumnie life_exp a tytuł legendy jest wybrany przez nas (rycina 16.4).
library(sf)
library(tmap)
data(World)
tm_shape(World, projection = "robin") +
tm_polygons(col = "life_exp",
title = "Oczekiwana dalsza \ndługość życia")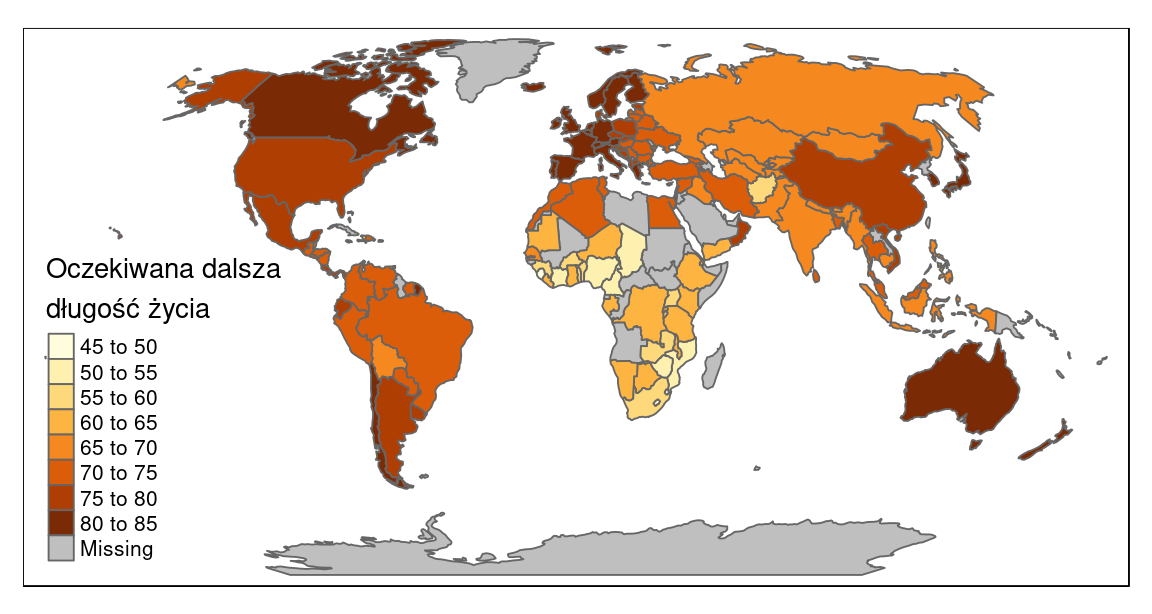
Rycina 16.4: Przykład działania pakietu tmap.
Podstawy działania na danych przestrzennych zawiera książka Geocomputation with R (Lovelace, Nowosad, and Muenchow 2019).
16.4 Programowanie w R
Wcześniejsze sekcje opisywały różne obszary zastosowań R, ale nie pokazywały w jaki sposób rozwijać umiejętności programowania w tym języku. Najprostszym sposobem jest używanie R jak najczęściej. Nauka języka programowania przebiega wówczas naturalnie - wraz ze znaleziskiem rozwiązania kolejnego problemu czy rozwiązaniem kolejnego zadania.
Często jednak, nie jesteśmy w stanie stwierdzić czy ten sposób rozwiązania jest optymalny, lub też napotykamy sytuacje w których nie wiemy jak się do nich odnieść. Wówczas szczególnie istotna jest inna umiejętność - czytania kodu innych osób67. Większość pakietów R jest otwartoźródłowych - ich kod jest dostępny online i każda chętna osoba ma do niego dostęp68. Kod pakietów R można, między innymi, znaleźć w serwisie GitHub. Wszystkie pakiety znajdujące się w repozytorium CRAN można znaleźć pod adresem https://github.com/cran. Inną możliwością jest samodzielne wyszukanie kodu pakietu używając wyszukiwarki GitHub - https://github.com/search.
Przykładowo, pod adresem https://github.com/karthik/wesanderson znajduje się kod źródłowy pakietu wesanderson (Ram and Wickham 2018).
Ten pakiet zawiera funkcje tworzące palety kolorystyczne inspirowane filmami reżysera Wesa Andersona.
Kod R będący podstawą działania tego pakietu znajduje się w folderze R/69.
Dodatkowo, niektóre pakietu zawierają kod z innych języków programowania (np. C lub C++), który wymaga wcześniejszej kompilacji.
Taki kod znajduje się w folderze src/.
16.5 Co dalej?
Programowanie to nie tylko pisanie kodu. Obejmuje to też wiele innych czynności, takich jak stosowanie optymalnych algorytmów czy narzędzi programistycznych. Istnieje wiele książek poświęconych kwestii algorytmów, wśród których najbardziej popularne to Introduction to Algorithms (Cormen et al. 2009), The Algorithm Design Manual (Skiena 2008) czy Algorithms (Sedgewick and Wayne 2011). Podstawowym narzędziem programistycznym jest program do pisania kodu. Może to być zarówno prosty edytor tekstu, taki jak Notepad++, Sublime Text, lub Atom czy też bardziej złożone zintegrowane środowisko programistyczne (IDE). O ile narzędzia z tej pierwszej grupy są uniwersalne to w przypadku wyboru IDE warto zdecydować się na zintegrowane środowisko programistyczne odpowiednie dla używanego języka programowania70.
Programowanie często obejmuje pracę w zespole. Wówczas jednym ze sposobów dbania o jakość tworzonego produktu może być inspekcja kodu (ang. code review). Polega ona na tym, że zmiany naniesione w kodzie są przekazywane innej osobie, która sprawdza go pod kątem błędów, spójności, stylu, zgodności z istniejącymi rozwiązaniami, itd. Po inspekcji twórca kodu może dostać informację zwrotną, co jest dobre, a co wymaga poprawy. W efekcie, z jednej strony wyjściowy produkt jest lepszej jakości, a z drugiej strony programista uczy się i polepsza swoje umiejętności.
Niezależnie od używanego języka istnieje również szereg narzędzi, których znajomość ułatwia lub czasem nawet umożliwia pracę. Wśród nich można wyróżnić znajomość linii komend i jej możliwości (Kross 2017) oraz języka SQL służącego do tworzenia, edycji i zarządzania relacyjnymi bazami danych (Beighley 2007; Forta 2013).
Innym kierunkiem działań może być nauka kolejnego języka programowania - najlepiej takiego, którego główne zastosowanie różni się od R. Może to być przykładowo język kompilowany, taki jak C, C++ lub Rust, którego efektem będzie bardziej wydajny program. Co ważne, kod napisany w tych językach można łączyć z kodem R. R posiada wbudowany interfejs do używania kodu napisanego w C (rozdział 5 z dokumentacji Writing R Extensions (R Core Team 2019)), łączenie kodu napisanego w C++ ułatwia znacząco pakiet Rcpp (Eddelbuettel et al. (2020); więcej informacji w rozdziale “Rewriting R code in C++” książki Advanced R (Wickham 2014)), a wskazówki dotyczące łączenia kodu Rust można znaleźć w repozytorium https://github.com/r-rust/hellorust. W efekcie użytkownik może korzystać z interaktywności R, wykonując dowolne linie kodu, ale część z nich może używać wydajniejszych funkcji napisanych w językach kompilowanych. Alternatywną drogą może być nauka języków używanych do tworzenia i rozwijania aplikacji internetowych, w tym JavaScript czy PHP.
Pomimo już znaczącej historii, języki programowania nadal mają wiele nowego do zaoferowania. Nieustannie następuje ich ewolucja - dodawane są nowe możliwości, zmieniane są istniejące funkcje, czy też następuje poprawa wydajności. Tworzone są również pakiety, moduły, czy biblioteki implementujące nowe pomysły, czy też ulepszające i rozszerzające dostępne oprogramowanie. W efekcie typowy kod napisany w danym języku kilka lat temu może się różnić od tego napisanego dziś. Powstaje też ciągle wiele nowych języków, z których tylko niewielka część zdobywa szersze grono użytkowników. Te języki często wprowadzają nowe podejścia i koncepcje, które później mają bezpośredni wpływ na zmiany w istniejących językach. Języki programowania są też stosowane coraz częściej w wielu codzienne używanych sprzętach, w tym samochodach czy lodówkach (ang. internet of things, IOT).
Powodzenia w dalszej przygodzie z programowaniem!
Bibliografia
Bache, Stefan Milton, and Hadley Wickham. 2014. Magrittr: A Forward-Pipe Operator for R. https://CRAN.R-project.org/package=magrittr.
Beighley, Lynn. 2007. Head First SQL: Your Brain on SQL–A Learner’s Guide. " O’Reilly Media, Inc.".
Cormen, Thomas H, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. 2009. Introduction to Algorithms. MIT press.
Eddelbuettel, Dirk, Romain Francois, JJ Allaire, Kevin Ushey, Qiang Kou, Nathan Russell, Douglas Bates, and John Chambers. 2020. Rcpp: Seamless R and C++ Integration.
Forta, Ben. 2013. Sams Teach Yourself SQL in 10 Minutes. Pearson Education.
Kross, Sean. 2017. The Unix Workbench.
Lovelace, R, J Nowosad, and J Muenchow. 2019. Geocomputation with R. Chapman and Hall/CRC Press.
Ram, Karthik, and Hadley Wickham. 2018. Wesanderson: A Wes Anderson Palette Generator. https://CRAN.R-project.org/package=wesanderson.
R Core Team. 2019. Writing R Extensions. R Foundation for Statistical Computing.
Sedgewick, Robert, and Kevin Wayne. 2011. Algorithms (4th Edition). Addison-Wesley Professional.
Skiena, Steven S. 2008. The Algorithm Design Manual. Springer Science & Business Media.
Wickham, Hadley. 2014. Advanced R. Chapman and Hall/CRC.
Wickham, Hadley, and Jennifer Bryan. 2019. Readxl: Read Excel Files. https://CRAN.R-project.org/package=readxl.
Wickham, Hadley, Winston Chang, Lionel Henry, Thomas Lin Pedersen, Kohske Takahashi, Claus Wilke, Kara Woo, Hiroaki Yutani, and Dewey Dunnington. 2020. Ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics. https://CRAN.R-project.org/package=ggplot2.
Wickham, Hadley, Romain François, Lionel Henry, and Kirill Müller. 2020. Dplyr: A Grammar of Data Manipulation.
Wickham, Hadley, and Garrett Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. " O’Reilly Media, Inc.".
Wickham, Hadley, and Lionel Henry. 2020. Tidyr: Tidy Messy Data. https://CRAN.R-project.org/package=tidyr.
Wickham, Hadley, Jim Hester, and Romain Francois. 2018. Readr: Read Rectangular Text Data. https://CRAN.R-project.org/package=readr.
Wilkinson, Leland. 2005. The Grammar of Graphics. Springer.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Chapman & Hall.
Kod
tavg ~ nazwa_stacjimożna inaczej odczytać jakotavgw zależności odnazwa_stacji.↩︎Analiza danych często jest określana również jako data science.↩︎
Ta książka również powstała używająć R Markdown.↩︎
Dodatkowo istnieje specjalne repozytorium Bioconductor poświęcone pakietom R dotyczącym zagadnień bioinformatycznych.↩︎
Read the Source, Luke.↩︎
Dostępny jest także kod źródłowy samego języka R. Można go znaleźć pod adresem https://github.com/wch/r-source.↩︎
Szczególnie
R/colors.R.↩︎https://en.wikipedia.org/wiki/Comparison_of_integrated_development_environments↩︎